
Understanding the Real Challenge of Keeping ML Models Working Smoothly in Production
You've built it. The machine learning model that took weeks to develop, test, and tune is finally ready. But here's the tough truth nobody talks about enough: getting it working in production is where the real work begins.
Most data scientists and ML engineers face a gut-wrenching reality once their models hit production. The performance that looked perfect in the lab suddenly drops. Users complain about weird predictions. The system grinds slower than expected. Something feels fundamentally broken, even though the code is identical.
This isn't incompetence. This is the gap between development and production—and it affects organizations of all sizes.
The Silent Problem Nobody Prepared You For
When your machine learning model moves from development into the real world, it encounters a landscape you never simulated. New data patterns arrive constantly. Customer behavior shifts. Infrastructure limitations kick in. The model that achieved 97% accuracy on your test dataset now struggles with real-world messiness.
Here's what typically goes wrong:
- Your model receives data it never saw during training, and confidence scores become unreliable
- The production server can't handle prediction requests fast enough, creating bottlenecks users notice immediately
- Nobody monitors what the model actually predicts, so problems pile up undetected for weeks
- The integration between your model and other systems creates unexpected bugs
- Memory usage balloons when models try to process larger batches than anticipated
- Team members can't explain what the model is doing or why it made specific decisions
Each of these problems seems small in isolation. Combined, they create production environments where models fail silently or crash unexpectedly.
The worst part? You can prevent most of these issues with planning and the right practices.
Why Smart People Make Expensive Mistakes Here
The challenge isn't that ML engineers are unprepared. The challenge is that moving a model to production requires thinking differently than training it does.
Development favors exploration. You test assumptions. You adjust parameters. You celebrate when accuracy improves by 2%. The environment is forgiving because failure is just feedback.
Production demands reliability. Users expect consistent results. Downtime costs real money. Errors need explanations. The environment is unforgiving because failure means consequences.
These two mindsets clash constantly. Engineers who master one struggle with the other.
- Data scientists focus on model performance while engineers focus on system stability—sometimes these goals compete
- The same team rarely handles both development and production, creating communication gaps
- Organizations underestimate the infrastructure and monitoring work that deployment requires
- Testing practices for ML models differ dramatically from traditional software testing, confusing engineers
- Cost and scalability surprises emerge only after production launch, forcing expensive redesigns
Many teams discover these challenges the hard way—after models fail in production and damage user trust or business metrics.
The Confidence Crisis That Stops Good Models From Growing
Deploying ML models creates a psychological burden most organizations don't acknowledge openly. Teams lose confidence in their own models when production problems mount.
When a model fails, people start questioning everything about it. Was the training data bad? Did someone make a wrong decision in feature engineering? Should we rebuild from scratch? The second-guessing becomes paralyzing.
Engineers feel responsible but powerless. They can't see into production clearly enough to understand what's happening. Decisions get made by committee instead of data. Innovation slows because nobody trusts new models enough to deploy them.
This cautious approach protects against catastrophic failures. It also prevents teams from improving models and building new ones. Organizations get stuck with outdated models because the deployment process feels too risky.
The real solution isn't avoiding risk—it's managing it systematically.
When you deploy ML models using proven best practices, you build confidence through visibility and control, not through caution and restriction. You know what the model is doing. You catch problems early. You can improve safely because you understand your monitoring systems.
This confidence changes how teams operate. Good engineers deploy more frequently. Models improve faster. The business sees measurable value instead of theoretical potential.
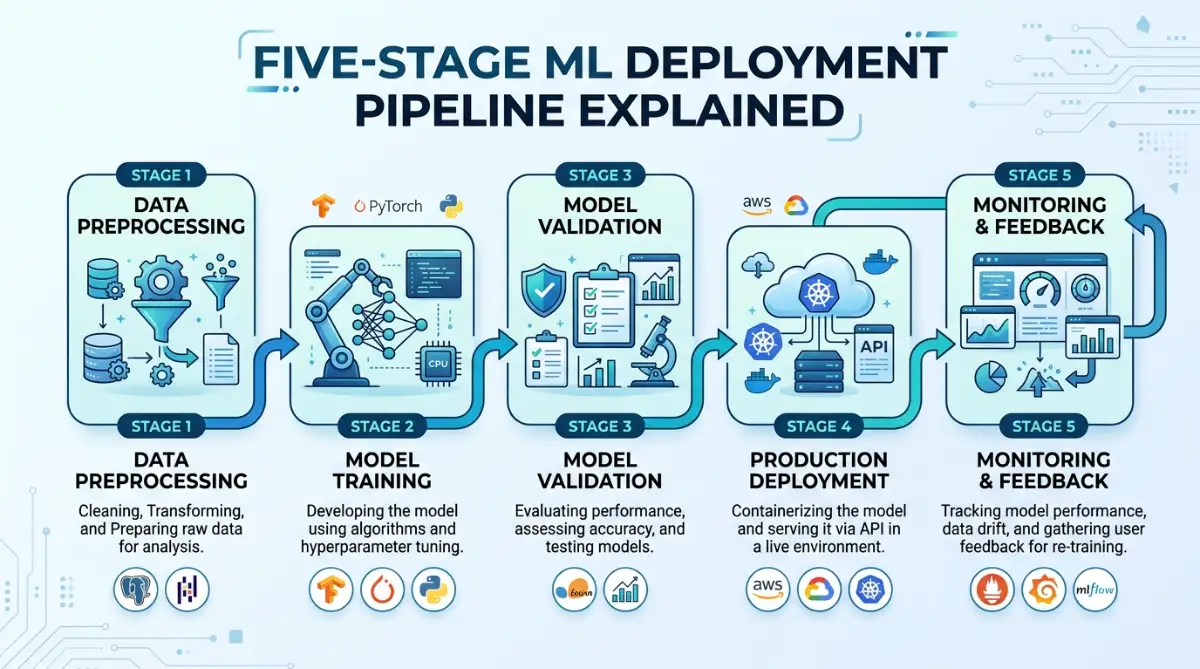
Building Reliable ML Systems: Proven Strategies That Actually Work
Step 1: Establish Data Validation as Your First Defense Line
Data quality determines everything in machine learning. If garbage enters your system, garbage predictions exit it—no matter how sophisticated your model is.
Think of data validation like quality control in manufacturing. A car factory doesn't wait until the finished vehicle drives off the lot to check if parts were damaged. They inspect at every stage because problems caught early cost pennies instead of millions.
Your ML system needs the same approach.
Start by defining what valid data looks like for your specific model. What data types should each feature contain? What ranges are reasonable? Which values would suggest something went wrong? Document these requirements clearly.
Then implement automated validation that checks incoming data before it ever reaches your model. This might seem like extra work upfront, but it's actually the fastest way to prevent production headaches.
When your model receives unexpected data—perhaps a feature has suddenly shifted from integers to text, or numeric values dropped below historically observed minimums—validation catches it immediately. You get an alert. You investigate. You solve the problem before predictions go wrong.
The technical implementation uses data validation libraries that scan datasets for schema violations, statistical anomalies, and other red flags. These tools integrate directly into your prediction pipeline, rejecting bad data automatically.
One practical example: imagine you've built a credit approval model that expects all applicants' income values as positive numbers. Suddenly, someone submits a negative income value by accident. Your validation catches this, raises an error, and prevents a nonsensical prediction from affecting real lending decisions.
Step 2: Create a Testing Strategy Specific to Machine Learning
Traditional software engineers test whether code does what the code says. ML engineers must test whether the model does what we expect from it—a fundamentally different challenge.
A function that adds two numbers either works correctly or it doesn't. A prediction model that improves accuracy by 0.5% might be working perfectly, or it might be overfitting dangerously. The distinction matters enormously.
Your testing strategy needs three components:
Unit tests verify that individual components work. Does your preprocessing code correctly transform raw features? Do prediction functions return results in the expected format? These tests are straightforward and crucial.
Integration tests check whether your model works correctly when connected to the larger system. Does the model receive data in the right format from your data pipeline? Does the prediction output integrate properly with your application? These tests prevent surprises when models interact with other systems.
Model-specific tests evaluate whether the model itself behaves as expected. This is where ML testing differs most from traditional software testing. You might test that prediction confidence scores stay within expected ranges, that the model handles edge cases gracefully, or that model outputs match your business expectations.
For instance, if you're building a model to detect fraudulent transactions, your model-specific tests should verify that the model catches most real fraud cases (high recall) while not incorrectly flagging legitimate transactions as fraud (reasonable precision). These tests require domain knowledge and careful design.
Version control extends to models too. Just as you track code changes, track model changes. When did you retrain the model? What data did you use? How did performance metrics change? This history becomes invaluable when investigating production issues.
Step 3: Monitor Performance Like Your Business Depends On It
It does depend on it.
The moment your model goes live, the learning doesn't stop—it intensifies. In production, you'll discover patterns that never appeared in your training data. You'll see edge cases you couldn't anticipate. You'll watch user behavior shift over time, gradually changing what data your model receives.
Without monitoring, you're flying blind.
Monitoring means continuously tracking how well your model performs in the real world. You're measuring different things than you did during training because production reality differs from lab conditions.
Start with predictions. Log every prediction your model makes: the input features, the predicted output, and the confidence score. This data becomes your window into what the model actually does when it matters.
Then measure business outcomes. If your model recommends products to customers, track which recommendations lead to purchases. If your model predicts equipment failures, track whether those predictions actually prevent problems. These metrics connect your technical model to business impact.
Set up alerts for when things go wrong. If prediction confidence drops unexpectedly, if the distribution of predictions shifts dramatically, or if real-world feedback suggests the model is missing cases, you want to know immediately. Not weeks later when somebody casually mentions that the model seems different.
The implementation uses monitoring dashboards that update continuously. These dashboards should be accessible to everyone who cares: the data science team, the engineering team, and business stakeholders. Transparency builds trust and surfaces problems faster.
One crucial addition: implement monitoring for data drift. Over time, the data your model receives will gradually shift away from the training data distribution. This is normal. It's also dangerous because models perform worse on data different from what they learned on.
Detecting data drift early lets you retrain before performance degrades significantly.
Step 4: Establish a Retraining Process That Keeps Models Healthy
Models don't stay accurate forever. Eventually, the real world changes enough that your model's accuracy suffers. This isn't a failure—it's inevitable in machine learning.
Retraining is how you maintain performance over months and years.
The question isn't whether to retrain, but when and how. Without a formal retraining process, models drift silently into irrelevance. With a process, you maintain performance systematically.
Start by deciding what triggers a retrain. Some organizations retrain on a schedule—every week, every month, or quarterly. Others retrain when performance metrics decline below thresholds. Most successful organizations use both approaches: regular maintenance retrains plus emergency retrains when problems surface.
Your retraining pipeline mirrors your original training pipeline but uses recent production data. This matters because production data reflects real-world complexity that your initial training data might have missed.
Automated retraining saves time and prevents human error. Instead of manually running training scripts when metrics dip, an automated pipeline detects the need, runs retraining, validates that the new model improves performance, and deploys it—all without human intervention.
This requires strong testing and validation because automatic retraining can introduce problems if not carefully managed. You never want a retraining process to deploy a worse model by accident.
Version control every retrain. Document which data was used, when retraining happened, and what performance changes resulted. This history becomes crucial for debugging when you notice a model behaves differently.
Step 5: Implement Model Explainability for Trust and Debugging
Users increasingly expect to understand why systems make decisions about them. A credit application declined by a model isn't just frustrating—it's potentially illegal if you can't explain why. Explainability matters both ethically and practically.
More importantly for production stability, explainability helps you debug. When something goes wrong, the ability to see why your model made specific predictions dramatically speeds up problem-solving.
Several approaches make models more explainable. Feature importance analysis shows which features most influenced each prediction. LIME (Local Interpretable Model-Agnostic Explanations) explains individual predictions. SHAP values quantify how each feature contributed to specific outputs.
Implement at least one explainability approach for any model users interact with directly. Even if you don't expose explanations to users initially, having them available internally helps tremendously when troubleshooting.
The Path Forward: Building Confidence Through Systematic Practices
You now have the framework for deploying ML models that actually stay reliable in production. The five strategies—data validation, testing, monitoring, retraining, and explainability—address the core challenges organizations face.
None of these is complicated individually. Each requires planning and some upfront work, but that investment saves enormous time and problems later.
Start with whichever challenge worries you most. If you're losing confidence in model predictions, begin with monitoring and explainability. If you're nervous about data quality, start with validation. If you worry about changes breaking things, start with testing.
You don't need to implement everything simultaneously. You need to start building a culture where production reliability matters as much as development innovation. That culture shift, combined with these practices, transforms ML from a risky experimental tool into a dependable business asset.
The teams deploying models most successfully understand that production isn't the endpoint of your ML work—it's where the real value generation begins.
Scaling Up Your Production Machine Learning Safeguards
Deploying a fresh model directly to your users is always a gamble. Even with great offline test scores, real-world data can surprise your system. This is why experienced engineering teams use quiet testing methods to protect their users.
One of the best ways to do this is through shadow deployments. In a shadow setup, your active system sends incoming data to both the old model and the new model. However, only the old model's prediction is sent back to the customer.
The new model runs quietly in the background, making predictions on real data without anyone knowing. We save these quiet predictions to a database and compare them against the active model. According to production guidelines on Google Developers, tracking this difference helps you catch bugs before they affect real users[1].
Imagine a co-pilot sitting in an airplane cockpit. They watch the main pilot make decisions and write down what they would do in their own notebook. The co-pilot does not touch the controls, but we can review their notes later to see if they are ready to fly.
This method is incredibly safe because a failing shadow model cannot crash your app. If the new model times out or makes bad predictions, only your background logs are affected. Your customer still enjoys a smooth experience served by the old, stable system.
During a shadow deployment, your engineering team must pay close attention to latency metrics. If the new model takes twice as long to process data as the old one, you have found a performance bottleneck. This discovery allows you to optimize your model's speed before any real customer experiences the lag.
Once you are confident in your shadow model, you can transition to a canary deployment. This approach involves routing a tiny fraction of your traffic to the new model. For instance, you might start by sending only one percent of your users to the new system.
We monitor this small group closely for any unexpected issues. If the system stays stable, we slowly increase the traffic to five percent, then twenty percent, and eventually one hundred percent. Research papers on the arXiv database suggest that this rolling method prevents widespread outages.
Think of it like testing a new recipe on a small group of friends before serving it to a giant wedding party. If your friends enjoy the food, you can confidently prepare it for everyone else. If they get sick, you only have to apologize to a few people.
Setting up automatic rollback triggers is a key part of any successful canary deployment. If the error rate for your one-percent user group spikes even slightly, the system should immediately direct all traffic back to the safe, older model. This automated safety net ensures that human errors do not ruin the entire user experience.
Designing a Safe Fallback Strategy to Handle Model Failures
No matter how much you test, your production models will eventually fail. A cloud server might go down, a data pipeline might break, or the model might time out. You need a backup plan to keep your business running during these stressful moments.
This backup plan is called a fallback mechanism. When your machine learning system fails to respond in time, your application should immediately switch to a simpler rule. This simpler rule is often a basic heuristic or a fixed database query.
For example, imagine you run a movie recommendation app powered by an advanced model. If the model fails, the system should not show an error message. Instead, the fallback system should instantly show the top ten most popular movies.
Your users will not even notice that the main model went down for a few minutes. They still see a working page, which keeps their trust high. A simple, working backup is always better than a broken, sophisticated system.
Engineers refer to this graceful backup strategy as degradation. Instead of failing completely, your application degrades gracefully to a simpler, less computational state. This design philosophy is widely used in high-traffic applications to ensure high availability.
To manage these fallbacks and upgrades, you must use a centralized model registry. A registry is like a digital library that stores all your trained models, their code dependencies, and their performance records. It acts as a single source of truth for your production systems.
If a newly deployed model starts behaving badly, the registry allows you to roll back to the previous version with a single click. We do not have to rewrite code or rebuild databases to fix the issue. We simply point our production system to the older, verified model in our registry.
This ability to quickly revert to a stable state is critical for making smart technology investments in your business. It reduces the stress of deployments because you know you can always undo your changes instantly.
A good model registry does not just store the model file itself. It also stores the exact version of the Python libraries, the training dataset files, and the evaluation charts. Having this complete package makes it incredibly easy to reproduce your results whenever you need to debug a problem.
Mastering the Data Feedback Loop with Human-in-the-Loop Reviews
Machine learning models are not static entities that you build once and leave alone. They exist in a dynamic world where user behavior and data patterns are always shifting. To keep them healthy, you need to build a continuous data feedback loop.
A feedback loop gathers new production data, cleans it, and uses it to retrain your model over time. However, completely automating this loop can be risky if the new data contains errors. That is why the best teams use a human-in-the-loop system.
In a human-in-the-loop setup, your model flags predictions where its confidence score is very low. For example, if an image classification model is only sixty percent sure about a label, it routes that image to a human reviewer.
A human employee then looks at the image, corrects the label, and saves it. This verified data goes directly into your training database. Over time, your model learns from its own mistakes by studying these human-corrected examples.
Imagine a senior manager reviewing the work of a new intern. The intern handles ninety percent of the easy tasks alone. The manager only steps in to help with the complex, confusing cases, which helps the intern learn much faster.
This human review step also protects your system from bad or biased training data. Since a trained professional reviews each flagged case, you can be sure that your retraining dataset stays highly accurate. This clean data prevents your model from slowly drifting into making bad predictions over several months.
Finding the right balance between automated learning and human review is an ongoing process. If you route too many cases to your human team, you will create a major bottleneck. If you route too few, your model's accuracy might slowly drop without anyone noticing.
Establishing a Long-Term Maintenance Playbook
Maintaining these advanced safeguards might sound like a lot of work for a small team. However, you can make the process highly manageable by setting up clear rules and automated alerts. The goal is to build a system that alerts you only when something truly needs your attention.
First, create a simple runbook for your team. This runbook should list the exact steps to take when a model alert goes off. It should answer basic questions like who to contact, how to roll back a model, and where to find the error logs.
Second, automate your alerts so they do not cause alarm fatigue. Do not send an email every time a single prediction is slightly slow. Instead, set up alerts to trigger only when performance drops below your acceptable limit for more than ten minutes.
In addition to real-time alerts, schedule a monthly review session with your data team. Use this time to look at the overall trends in your data drift, model latency, and business outcomes. This regular check-up helps you spot slow, quiet changes that daily alerts might miss.
By keeping your alerts focused and your runbooks simple, your team can maintain multiple models without burning out. This systematic approach allows you to scale your artificial intelligence projects safely as your business grows.

Critical Mistakes That Can Destabilize Your Production Systems
Mistake 1: Treating Machine Learning Code Like Standard Software
Traditional software is built on clear, logical rules that you write directly. If you write a function to calculate tax, it will produce the exact same output every single time. Machine learning is completely different because its behavior depends heavily on real-world data.
Many teams make the mistake of testing only the code and ignoring the data. They write unit tests for their APIs but forget to check if the incoming data matches the training data. This mistake leads to silent model failures where the code runs perfectly but the predictions are totally wrong.
To avoid this, you must treat data as a dynamic code dependency. You need to test your data pipelines just as strictly as you test your application code. This is a key step when evaluating software tools for your company.
Mistake 2: Building Overly Complex Infrastructure Too Early
It is easy to get excited about advanced technologies like real-time streaming pipelines and massive cluster managers. Many teams build highly complex systems before they even know if their model brings any business value. This mistake drains your budget and exhausts your engineering team.
A complex system has many moving parts, which means there are many more things that can break. When a problem occurs, finding the root cause becomes incredibly difficult. Your team ends up spending all their time fixing infrastructure instead of improving the model.
Start as simply as possible. If your business only needs predictions once a day, use a simple batch job that runs overnight. You can always upgrade to real-time streaming later once your model has proven its worth.
Every server you rent and every pipeline you build requires ongoing maintenance and monitoring. If your small team is busy maintaining twenty complex pipelines, they will not have time to build new features. Keeping your setup simple preserves both your budget and your team's energy.
Mistake 3: Overlooking the Need for an Emergency Fallback Rule
Some teams assume their machine learning models will always be online and working perfectly. They do not write any backup rules for when things go wrong. When the model eventually fails, their entire application crashes, leaving users frustrated.
Imagine a ride-sharing app where the pricing model suddenly goes offline. Without a fallback rule, customers cannot book rides because the app cannot calculate the price. The business loses thousands of dollars in a matter of minutes.
Always design your systems under the assumption that your model will fail. Create a simple, hardcoded rule that can take over immediately when the main model goes down. This basic precaution keeps your business safe and your users happy.
When an outage occurs, the user experience should be seamless and clean. If your fallback rule displays a generic error code, your customers will feel anxious and confused. A friendly, helpful backup message keeps the interaction positive even when the backend is struggling.
Mistake 4: Relying on Schedules Instead of Dynamic Alerts for Retraining
A common mistake is setting up your system to retrain your model on a strict calendar schedule, like every Sunday night. While this sounds organized, it can lead to major problems if you do not validate the results. You might accidentally deploy a worse model trained on corrupted data.
For example, if your website experiences a strange bot attack on a Friday, your training data for that week will be highly skewed. An automated schedule will train a new model on this bad data and deploy it automatically. Suddenly, your system starts making terrible predictions for real customers.
Instead of relying purely on schedules, set up dynamic alerts based on data drift and performance drops. Only trigger retraining when your monitoring tools show that the model actually needs to learn from new patterns. Always run automatic validation tests on the newly trained model before it goes live.
Never let an automated training pipeline deploy a model without comparing its performance against the current active model. If the newly trained model scores worse on your validation test set, the deployment must stop immediately. Your system should send an urgent alert to your engineering team to investigate the issue.
Mistake 5: Failing to Align Model Metrics with Business Value
Data scientists often focus entirely on mathematical metrics like accuracy, precision, and recall. They spend weeks trying to improve a model's F1-score by a fraction of a percent. However, they fail to ask if this mathematical improvement actually helps the business.
If your model is highly accurate but takes five seconds to load, your users will leave your website before they even see the prediction. In this case, the highly accurate model is actually worse for your business than a slightly less accurate model that loads instantly.
Before you build any model, define how you will measure its success in the real world. Track business outcomes like customer retention, click-through rates, or processing times alongside your technical metrics. This alignment is essential for making smart tech purchase decisions that drive real growth.
Sometimes, a simpler model like a decision tree is much better for production than a deep neural network. The decision tree might be slightly less accurate, but it runs ten times faster and uses a fraction of the server memory. Always consider these practical system trade-offs before choosing your model architecture.
Empowering Your Team for Sustained Production Success
Moving a machine learning model from development to production is a journey that requires patience and a systematic approach. It is not just about writing great code or training highly accurate algorithms. It is about building a reliable system that can handle real-world messiness.
By implementing the advanced strategies we explored today, you can protect your business from silent failures and costly downtime. You do not need to build everything at once. Start by picking one key area, like data validation or a simple fallback rule, and build from there.
As your team gains confidence, you can add more sophisticated tools like shadow deployments and automated feedback loops. This steady progress will turn your machine learning projects into highly dependable assets. You will be able to launch new models quickly and safely, knowing your systems are built to last.
If you are ready to explore more tools that can help your team succeed, look into modern smart software platforms that simplify model management. With the right practices and the right tools, you can bridge the gap between development and production once and for all.
The path forward is clear. Take ten minutes today to evaluate your current deployment workflow, find your biggest blind spot, and take one small step to secure it. Your future self, your team, and your customers will thank you.
Disclaimer: This article is for general informational and educational purposes only and does not constitute technical, financial, or professional engineering advice. Machine learning production practices, model behaviors, and infrastructure costs may vary significantly based on your specific system requirements, cloud providers, and data qualities. Always consult with certified software engineers, data compliance experts, and system architects before deploying machine learning systems in a live production environment.


